


Performing SaaS application background tasks with AWS Batch and AWS Step Functions
Even the tiniest web application has to perform a lot of background tasks, be it image resizing, product/stock imports and report or sitemap generation. In addition, if your product is distributed in SaaS model, then most of them have to be performed for each of your customers.
That, depending on how popular your product is, may in turn require tons of computing power. You will have to find a way to quickly add and maintain all kinds of jobs, without adding too much technical debt to the project.
Oh, and without blowing your application up whenever a heavy job is running.
At first, it may be tempting to just let the web application be their executor and scheduler. Add an @Scheduled annotation, if you live in Java’s world, or a node-cron and voila – your application has a background tasks mechanism.
It works fine… but it also causes some fundamental problems. As soon as you run a second instance of your application, you have to synchronize your state between apps, otherwise you schedule the same task twice. Even worse – any fluctuations of resource usage (a “busy” task or a sudden spike in requests) can heavily impact the performance of the application. Your service could end up unreachable for end users, because a very CPU heavy task has consumed all the resources. This is nothing short of a nightmare, especially in the SaaS world with “noisy neighbors”.
Of course, you may add a synchronization mechanism between the tasks (and also code all the failure handling, retries or internal queues), schedule them to process only at night and so on. This is often the fastest method, but it leaves you with huge technical debt and does not scale too well.
Can you do better? Well, you may split your app into an app-web and app-worker and detach the latter from handling the web requests. Various frameworks like Django support this, although it requires running queues like Celery or RabbitMQ. Now, the failures and memory errors of your tasks no longer affect end users. Surprise traffic spikes don’t suddenly blow up your background task. This is way better, but still requires you to manage and scale the worker cluster on demand. There is also a lot of shared code between the app-web and app-worker, which could both confuse developers and further grow the technical debt.
Can you do (even) better? Well, why not let the web applications do the web part only? Let the worker applications be truly workers? Bind your tasks into lightweight, abstract containers that are ran on-demand, when necessary, with all the metadata collected from the outside. This is a common pattern in the data engineering/science world, where a huge DAG (directed acyclic graph) of various connected tasks is scheduled and executed on a daily basis. Using the right tools, you don’t need to be a data engineer to bring such quality into our web applications – you just need to use the cloud to its full extent.
To achieve this, two major pieces are needed:
First, an easy to use container environment, which automatically provides compute resources and runs containerized jobs.
Second, something to orchestrate the entire process. Thankfully, AWS has got us covered, specifically with the two technologies mentioned in the article’s title (a surprise huh?).
AWS Batch is, as the name suggests, a batch processing service. It is able to run hundreds of containers, providing as many compute resources as necessary. With its built-in queue all you need to do is define and trigger a job. AWS Batch will handle the execution part for you.
AWS Step Functions is an orchestrating service, based on a state machine. We define what should happen and in what order. The “what” could be a Lambda Function, a Fargate container, an AWS Glue job or an AWS Batch job (among few others). Step Functions (SFN) trigger all necessary “whats”, pass data between them, are able to run tasks in parallel, have some branching if/else logic and can be scheduled as needed.
The know-how
The components
The architecture below is generic and works in most of our tasks. You will be able to abstract the logic concerning your particular task and reuse literally 90% of your Infrastructure as Code (IaC) whenever you encounter a similar problem. As always, CDK or Terraform is great and you should definitely use it.
The general idea is:
Chunk the job into smaller, parallelizable parts (this is a piece of cake in SaaS applications – you could just run the same job for each tenant)
Run each of them in a separate container
Have the entire process scheduled, if necessary
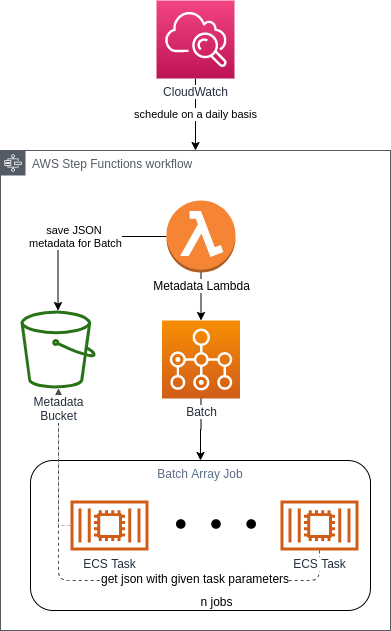
Metadata Lambda
As a starting point to our workflow, we have a Lambda Function for deciding how many tasks AWS Batch needs to run. This entirely depends on your use case – if the task is to resize images then “a portion of the job” could be an array with a thousand ids. Each container would get thousands of photos to process – all unique to that respective container, too. If a sitemap is to be generated or products are to be imported, then one task could handle exactly one tenant.
This is also a good place to handle any special logic – maybe some of your tenants require more parameters? What if a few of them should be ignored? Was the last execution for a given tenant successful and further computations are unnecessary for now? Answer similar questions yourself and code the logic accordingly. Do also note that this could be a container instead of a Lambda if 15 minutes of execution time is not enough to decide how big your job should be.
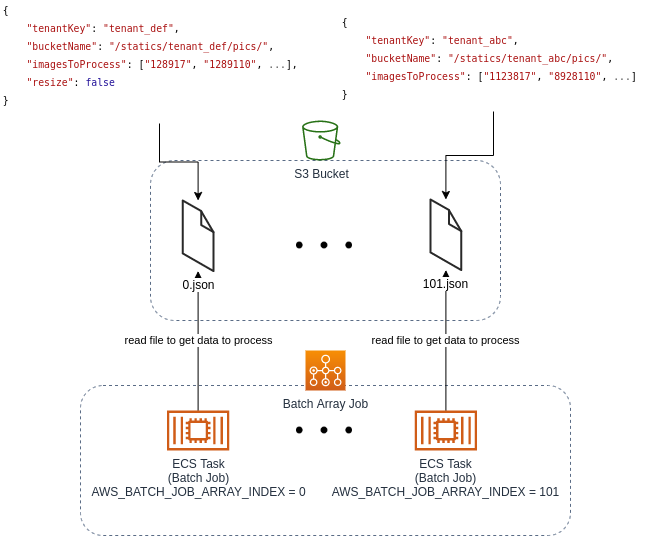
The metadata Lambda generates n sets of parameters (each set corresponds to “a portion of the job”) and saves them to an S3 bucket. We could also let the Step Functions pass the output from Lambda directly to AWS Batch (with no S3 involved), but there are various limits on how big (in kilobytes) the Step Function’s state can get. Our solution is more future-proof.
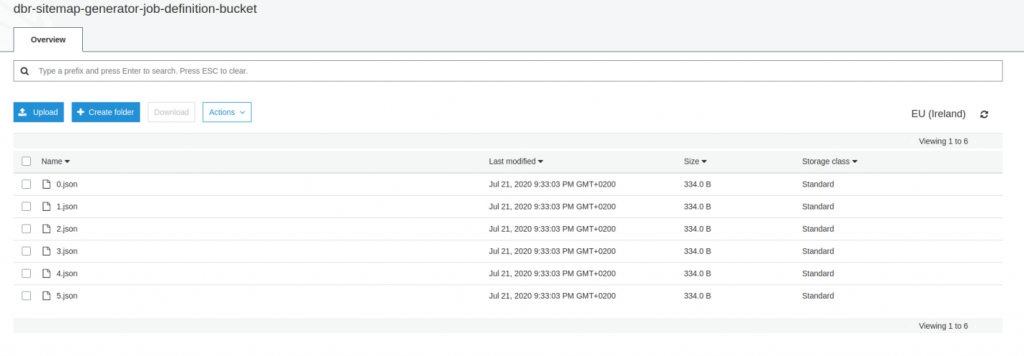
Metadata Lambda results file – json “chunks” with job specifications
Batch Job and the Container
Batch Job Definition is rather straightforward – all you need to specify is how much vCPU or memory will be used by a single ECS Task, as well as the its specific Docker image. The type of the job we are using here is called Array Job – n parallel independent containers are to be run on the Compute Environment.
The container is a tiny application and its sole purpose is to run the parameterized task it was designed to perform, exiting after the work is done. Consequently, the app often resembles more of a script-ish file than a fully-fledged application.
Furthermore, the code inside has to be as generic and reusable as possible – no hardcoding allowed! The first step is to read the S3 Bucket file using the AWS_BATCH_JOB_ARRAY_INDEX environment variable to get exact parameters – each container instance has its own unique number. That file, created by Lambda, should contain all the information required by the task – such as the tenant name, tenant bucket name and a thousand image IDs to process.
Batch Compute Environment and Job Queue
After the Batch Job is scheduled, the tasks are put into the Job Queue, where they wait be executed on a Compute Environment. These are pretty much ECS Clusters mixed with ASG/Spot Fleet and come in different colors and sizes types – you can either use your own ECS Cluster or let Batch manage the ECS Cluster for you. We have been successfully using Batch-managed clusters with Spot Instances to save some pennies. You only need to specify the minimum and maximum number of vCPUs. If you set the minimum to 0, the cluster will automatically scale its resources to nothing if no jobs are running. Pay as you go!
You can also indirectly define the maximum parallelization of jobs here – if a container requires 4 vCPU, your cluster is using a maximum of 2 EC2 instances with 4 vCPU each, then at any given moment, at most, 2 tasks will be running. The rest of them will gently wait in the Job Queue to be picked up and processed at a later time. Similar reasoning can be applied with Memory. This is a great way to ensure you don’t kill your database or other resources.
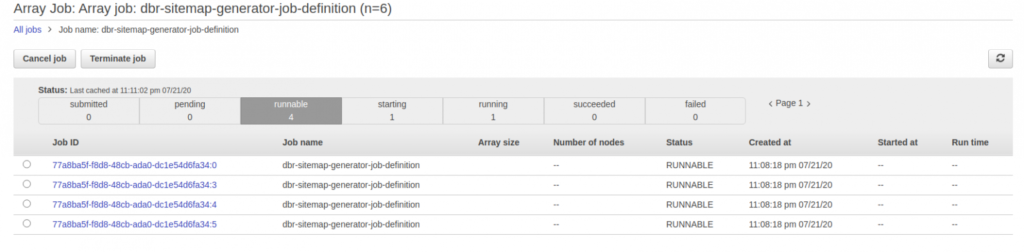
It might be worth noting that a Job Queue can have multiple Compute Environments assigned. You may try running your job on spot instances first (using arbitrary Compute Environment A), but if no resources are available fallback to on demand ones (using Compute Environment B). You can also specify multiple EC2 instance types a Compute Environment is allowed to run. Depending on the workload AWS Batch will try to acquire an instance suited to the current demand in the Job Queue.
Step Functions workflow
Step Function governs the entire process, gluing other components together. With its rich integrations with other AWS Services you are able to trigger a Lambda function (or a Fargate container) and schedule a Batch Job. You define the entire workflow and its order of execution here, in the State Machine. Should the workflow fail at some point, you could also define an error handler. Our example is rather simple, but you might for example want to store all failures and successes in a database for historic reasons, perform more tasks after the Array Job is finished, send an email to each tenant or trigger analytic jobs in AWS Glue. Possibilities are nearly endless.
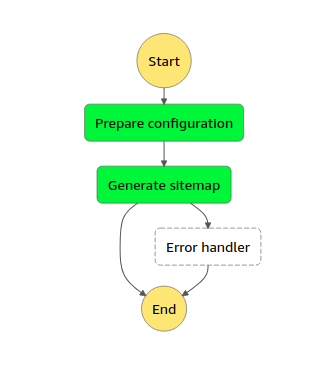
Other Batch functionalities
We have shown a rather simple workflow – an array of parallel, independent jobs. Batch itself provides more capabilities. Jobs can be dependent of each other and pass parameters within AWS Batch itself.
N to N jobs
In a common scenario where a lot of data for each of our tenants has to be imported, we might be interested in splitting the job into even smaller chunks. Import is not only about getting metadata from external resources and saving it in to database. The process often contains many smaller steps, such as data validating, fetching additional attachments (documents or images) or transforming to required model data or format in a specific order. If we have to import images, we generally want to scale them, change the format and perform a few other operations. These seemingly simple operations can consume a lot of resources in our system (and bring headaches to the Site Reliability Engineering (SRE) team if it was performed in the web application serving the requests).
Thankfully, AWS Batch allows us to split our long process into smaller chunks. Instead of one long running container performing all the operations, we can process data in multiple, smaller containers with their responsibilities narrowed down. The first container pulls the data into our system, the second one fetches the images and the third rescales them. If rescaling fails at some points, we do not need to redownload the images again – we can simply retry the container with the rescaling part. This also makes the development and testing of such little applications easier.
Using a Batch Array N to N Job, we are able to define a linked-list of dependencies. Job A has to finish first, passing the data to Job B. After that one finishes, Job C is started. The entire process is also an Array Job, so it can be performed for each tenant independently.
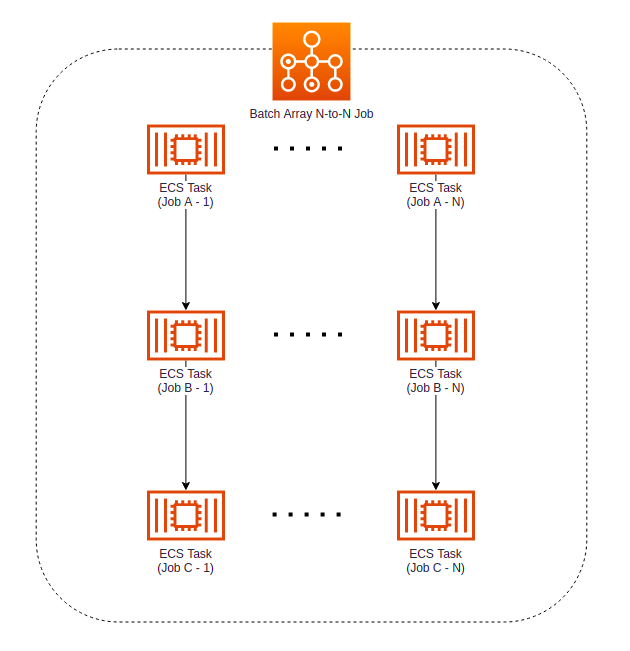
Note that it may be tempting to use Step Functions instead and design that kind of workload as follows:
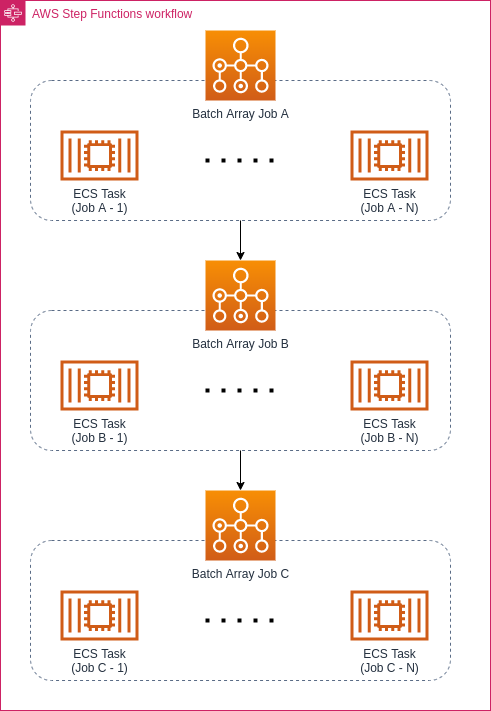
However, there is a subtle difference – if you define it as N to N, then each sequence of jobs runs separately. One of your tenants with a little data can finish the entire sequence quickly, while the others are still at the “Job A” stage. If you use Step Functions instead, all “Job A” tasks must finish before any “Job B” starts. Unless you need it to function that way, you’re often better off with N to N because the workload finishes faster and parallelizes slightly better.
Multi-Node Parallel Jobs
Another interesting capability is the multi-node parallel job, which allows you to run a single job on multiple EC2 instances. This differs from a standard job, which occupies only a single EC2 instance. Multi-node jobs are used for large-scale, high-performance computing applications and distributed GPU model training. This is fully compatible with most machine learning frameworks supporting IP-based, internode communication, such as Apache MXNet, TensorFlow, or Caffe2.
If you want to use multi-node parallel jobs on AWS Batch, your application must be prepared to run on multi-node infrastructure, so the code must use frameworks suitable for distributed communication.
Each multi-node parallel job consists of the main node, which is launched at the beginning. After that node is up, the child nodes are launched and started. Forget about compute environments that use Spot Instances, though – multi-node parallel jobs don’t support them. Regardless, you should look into AWS Batch if you’re looking for easy to use and disposable data science compute environments.
The quirks we have noticed
Batch gives little to no insight from its UI
Unfortunately, we haven’t been able to extract much information from the UI. If something blows up, you are forced to juggle between Batch, ECS, CloudWatch and Step Functions to find out what exactly happened and why. The community has so far made projects like batchiepatchie to mitigate the issue and provide a different AWS Batch UI. No moves or official plans from AWS, however.
Batch reacts at a snail’s pace
You might quickly become annoyed by how slow Batch reacts to events. Everything there seems eventually consistent:
- You schedule a job and you wait until it gets picked up and put in the Job Queue.
Then you wait until the Compute Environment notices there are tasks in the Queue – but not enough vCPUs to handle it.
Then you wait until it adjusts the desired capacity.
Then you wait until Spot Fleet/ASG actually gets the signal to scale up.
A few more “then you wait“ moments later… the task is finally running.
Nothing here seems instant – which of course isn’t much of a problem in background long-running tasks, but might be irritating, especially while developing the solution. The feedback loop is unrushed.
Step Functions are a challenge to debug (and develop)
Well, the definition of a State Machine is just a horrendous JSON file. When you make a mistake there (or even better – mix it with String interpolation from Terraform), then no IDE will save you. Even the built-in editor in AWS Console fails to provide meaningful error messages. Tests? Forget about it.
Also, no IDE helps you with the input/output processing syntax of SFN. All those $ and .$ take some time to get used to.
A great and useful rant about Step Functions can be read here on Reddit – so just know that you’re not alone on this!
Launch Configuration of managed Compute Environment with Spot Instances
There is some magic happening behind the scenes whenever you create Managed Compute Environments with Spot Instances. During creation, you may specify a Launch Template to be used by the EC2s. If Spot Instances are also selected, Batch creates a Spot Fleet Request on your behalf (you have attached AmazonEC2SpotFleetTaggingRole, have you?).
Because Spot Fleet Request requires Launch Templates as well, the one from Compute Environment gets copied. But then, any changes applied on the Compute Environment’s Launch Template are not propagated to the Spot Fleet Request’s Launch Template. Our IaC tool of choice (Terraform) was not able to help us there and we spent some time debugging and asking “why doesn’t the cloud-init script change even though the Launch Template does?”.
Content-Type of Launch Template
This is of course written somewhere in the docs – make sure any Launch Template is a MIME multi-part file (this is shown just below)!
Authentication in a private repository
ECS is able to pull images from private registries using a handy repositoryCredentials in task definition. Unfortunately, Batch does not support that parameter. If you want to use a protected, private repository you have to ensure the EC2 on which the ECS Agent run has configured ECS_ENGINE_AUTH_DATA. You may either bake that into the AMI or add a script similar to this one in the Launch Template of the Compute Environment. This one pulls credentials from AWS Secrets Manager – make sure your instance will have permission to perform that API call!
MIME-Version: 1.0
Content-Type: multipart/mixed; boundary="==MYBOUNDARY=="
--==MYBOUNDARY==
Content-Type: text/x-shellscript; charset="us-ascii"
#!/bin/bash
CREDENTIAL_ARN=<fill this>
REGISTRY_URL=<fill this>
CONFIG_FILE="/etc/ecs/ecs.config"
sudo yum install -y jq unzip
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
unzip awscliv2.zip
sudo ./aws/install
echo "Setting up ECS credentials!"
JSON=$(/usr/local/bin/aws secretsmanager get-secret-value --secret-id ${CREDENTIAL_ARN} | jq -r .'SecretString')
echo ECS_ENGINE_AUTH_TYPE=docker >> $CONFIG_FILE
echo "ECS_ENGINE_AUTH_DATA={\"${REGISTRY_URL}\": $JSON}" >> $CONFIG_FILE
sudo stop ecs && sudo start ecs
--==MYBOUNDARY==The data engineering struggles
This is our current go-to template for batch processing and performing background tasks in one of the SaaS projects we maintain and develop.
Can you (still) do better? Well, the real question at this point is would you use Step Functions as a fully-fledged workflow orchestrator with Batch as an execution engine? Are they good enough for data engineering projects?
As a starting point, in the MVP phase of an arbitrary project or product – without a doubt. Step Functions are easy to pick up, have enough integrations with other AWS services (like Glue or Batch – very handy in the data world) and work really well in not-so-complicated environments. Issues arise when connections and dependencies between tasks are no longer not-so-complicated.
The idea behind Step Functions is a state machine – we observe the current state of the flow and decide what should be done next. Basically, a Step Function is an overcomplicated if/else machine. In data engineering, it is way more convenient to think in Directed Acyclic Graphs (DAGs) – do the first task, then simultaneously those two, combine the results in the next task and so on. Unfortunately, this type of thinking is not supported by SFN and there is no other AWS product which could be used instead.
What about the other types of Batch Jobs we have mentioned? Couldn’t they simulate the DAG? Well, if you can fit into their requirements, they could work for a while. Sooner or later though, your branching logic will get more complicated and Batch will no longer be enough. Fighting with a framework (either SFN or Batch) won’t be easy.
There are also several red flags – when one of your SFN tasks blows up, you can’t just patch it and pick up where you left off. The entire job is marked as a failure and you have to restart the entire graph. This (along with a not-so-pleasant debugging/testing experience and parallelization/branching limits) automatically rules SFN out of data engineering projects, where computations often take hours to complete. There are of course retry mechanisms but they are not enough. We would recommend using Apache Airflow or a similar tool as a DAG scheduler for your data engineering needs. You may run it on AWS EKS, if you wish, and fully integrate with your other AWS tools.
The judgement
Thankfully, the majority of web applications’ background tasks aren’t that complicated and don’t depend too much on other jobs. Resizing images, generating sitemaps or reports all can be done independently. In the world of SaaS, they can also be parallelized for each tenant separately. This makes a great use case for SFN and Batch – as shown above.
Is it the best solution on the market? Like most things in IT, the answer depends on the scale and requirements of your project. You could use the standard periodic job provided by the framework your web application uses. The implementation will probably be swift, with no interference in the project’s infrastructure.
However, looking at the tradeoffs, this will become dangerous and overload your system, especially if your business model is SaaS. A slight increase in number of tenants would directly “contribute” to the application’s performance and technical debt. The last thing your business needs is an application blowing up because one of your customers has a lot of images to process.
With various AWS technologies already buried deep into the code and the product getting traction, the decision was trivial for us. The combination of CloudWatch, Step Functions, Batch, Lambda and S3 allows us to process large amounts of data with no impact on our system. If you are in similar place right now, you should definitely give it a shot.